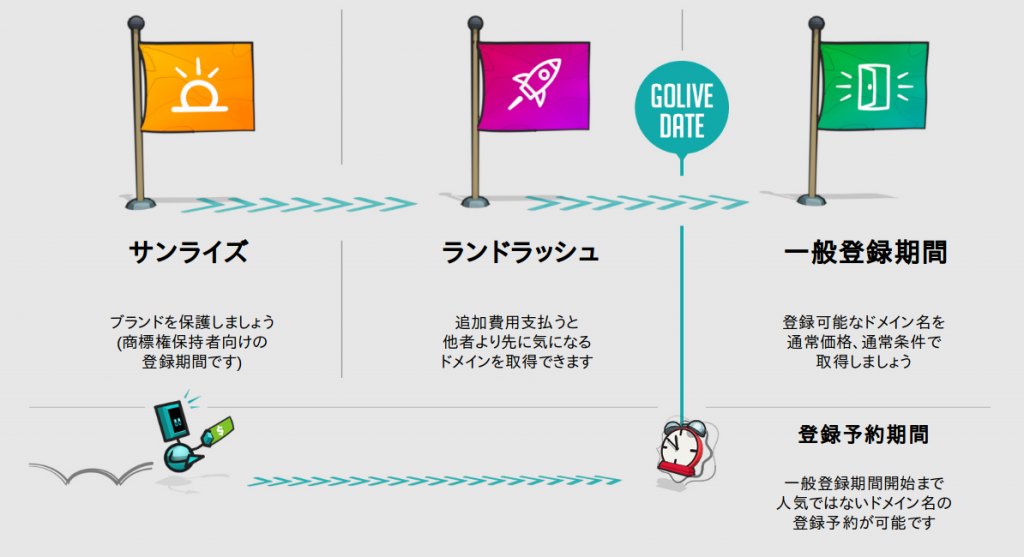
新しいTLD 「.PAGE」のサンライズ期間(*2)が8月27日(月)に始まります。
このサンライズ期間は10月2日まで続き、登録されている商標(*3)に対応する .PAGEドメインの登録が開始されます。初年度の .PAGEドメインのサンライズ期間中の登録は1,468円になります。
10月2日から10月9日までは .PAGEのランドラッシュ期間になります。この期間中は、一般登録期間に入りTLDが誰でも登録できるようになる前に、通常価格よりも高い価格でドメイン名を取得しておける期間です。ランドラッシュ期間中は一般登録期間開始まで、日によって .PAGEドメインの取得価格が異なります。ランドラッシュ期間初日である10月2日の価格は1,114,109円(*1)で、取得したいドメイン名がまだ残っている場合は10月9日の価格は17,774円になります。
一般登録期間は10月9日から始まります。価格は通常登録価格の1,722円になり、この日以降同じ価格になります。一般登録開始日前に申請された登録予約をこの日にGandiが .PAGE のレジストリに提出され、申請順にドメイン名がまだ登録可能な場合に登録が開始されます。
多くのTLDと同じように、.PAGEのレジストリが「プレミアムドメイン」だと決めたドメイン名には、登録可能日に関わらず特別なプレミアム価格が適用されます。もし後々人気になりそうなドメイン名を取得するつもりで、しかもそのドメイン名がプレミアムドメインである場合、ランドラッシュ期間中に、ランドラッシュ価格とプレミアム価格を支払うと先行登録をすることが可能です。
ご注意ください: .PAGEドメインは誰でも登録できますが、そのレジストリである Charleston Road Registry (Googleのレジストリ)では、.PAGEを使用するウェブサイトは全て SSL/TLSを使用する必要があります。 (Gandiのシンプルホスティングの「Small+SSL」を使用すれば利用可能です)
現在 .PAGEはサンライズ期間ですが、ランドラッシュ期間や一般登録期間での登録を今から申請することが可能です。申請をすると、.PAGE登録予約は一般登録期間開始まで保留され、一般登録開始後に申請内容がGandiからレジストリに提出され、登録が随時開始されます(*4)。
あなただけの .PAGE ドメイン名を探してみましょう!!